


用了几年的Sony电纸书电池快不行了,于是对比一番之后还是入手了一台iPad Air,想着平时看书,也能在短途出门时候当数码伴侣备份照片之类,免得带手提电脑。几乎主流的读书软件我都用了一下,最后还是发现很难有一个非常全面能打的选择,目前还是在MarginNote、Goodnotes、PDF Expert、iBook里读不同场景、不同格式的文档或书。读书,就会遇到扫描版的问题。MarginNote购买OCR订阅后可以边看边识别,但似乎只能在app内用;Goodnotes是一次性付费升级后可以识别手写笔记,但对文档自身不做OCR;PDF Expert升级OCR或转换文档格式,得49刀的年费。我自己有扫描仪,也在用支持LiveText的macOS、iOS设备,所以从这两个角度动了动脑筋。
一、充分利用扫描仪自带的软件
多数国际品牌的扫描仪都是自带Abbyy FineReader,比如我是ScanSnap,就是自带Abbyy FineReader for ScanSnap v5.5,其macOS版还是Intel芯片的,功能上并没有什么问题。FineReader识别率是有口皆碑的,我还曾经买过单行版。但是最近两三年FineReader大概也意识到生意艰辛,改成订阅制了,我买过的单行版直接就不能用了,令人气愤啊;而for ScanSnap版如果打开非扫描仪生成的PDF会告知限制后退出。如果能让所有的PDF用上for ScanSnap版,那还是很香的。
我测试了一下,其实for ScanSnap版本就是靠读取PDF文件的元数据来判断并限制的,具体来说是要求PDF的Creator对应你的扫描仪型号。那就简单了,调用一个pyPDF库就能解决的问题。具体代码放Github上了。顺便说一句,pyPDF库似乎把原来的pyPDF2、pyPDF4之类都大一统了,也更加简单好用了。
当然,这种方法也是一种“破解”,并不符合版权要求(我是用好像100多刀买过单行版,自我感觉还是可以安慰一下的哈)。
二、直接用macOS的OCR能力
macOS Monterey开始有了LiveText,特别是在有ML芯片的Apple Silicon机器上,性能和准确性是很不错的。我也是这几天研究这个问题才发现macOS 13开始,自带的预览已经支持OCR识别后在PDF嵌入文字,具体的方式就是文件——导出——勾选嵌入文本。根据文档大小,预览会开始识别,完成后保存。
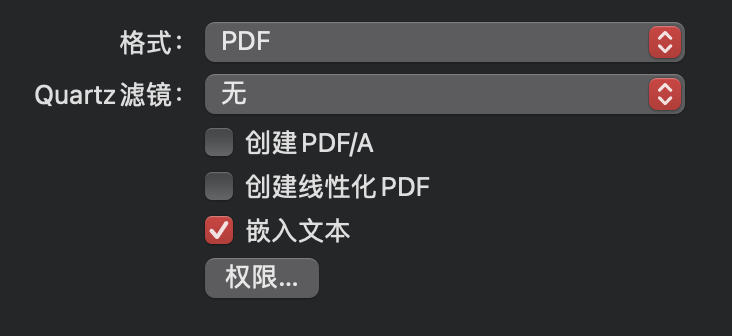
三、两种方法比较
用这两种方法识别了一个410页的PDF文件,其扫描分辨率应该是低于300dpi的(因为FineReader一边识别一边抱怨……)。从输出看,FineReader最后生成74M的文件,预览生成的文件63.4M;没有精确计算时间,但是FineReader至少是2倍以上;过程中FineReader基本是靠CPU,在300-400%的占用率,预览是亲生的,基本不影响任何其他操作,CPU就是个50%以内;结束后,FineReader生成大量Compressed内存,预览感觉不明显。我用FineReader连续识别了大概10多个扫描文档后(自己扫的300-600dpi,有黑白有彩色),M1 Pro、32G内存的电脑卡得不行,但奇怪的是CPU不高、内存也并没有用上Swap,我只能理解是Rosetta 2转译的问题?
最后是文档的准确性,为了方便对比,我用code block展示吧:
--FineReader(下面空格是软件自己加的)
呈现在读者面前的是一部有关苏联74年兴衰历史的实证性专题研究著 作,由24名中国学者合力完成,书中涉及政治、军事、外交、经济、文 化、民族、宗教等各个方面,共28个专题,总计约130万字。
--Preview(下面空行、空格是软件自己加的)
呈现在读者⾯能的是⼀部有关 苏联 74 年兴衰历史的实 证性 专题研究著
⽂ 作 ,由24 名中国学者合⼒宛成,书中洗政政治、年事、外交、经济、
化 、民族、宗教等各个⽅⾯,共28 个专题 ,总计约 130 万字。
可以看出FineReader还是靠谱很多,只是多了2个空格,文字完美;预览拿来应个急也是可以的,无故多了空行、也有一些错字。
现在ML越来越厉害,相信类似文字(特别是印刷字体)、语音识别转写之类的都会普及成为基础功能了。